白少进,白 静,2,司庆龙,姬 卉,袁 涛
1.北方民族大学 计算机科学与工程学院,银川 750021
2.国家民委图形图像智能处理实验室,银川 750021
随着计算机辅助设计技术和计算机图形学的快速发展,三维模型的数量与日俱增,三维模型的识别问题也变得日益复杂,出现了多样化的分类需求[1-3]。现有研究主要聚焦于一般性的三维模型分类,无法满足多样化分类需求;
而部分针对特定需求设计的分类工作也只能适应相应任务。如何构建普适性三维模型分类框架,以使其适应不同需求的分类任务具有相当的挑战性。
深度学习技术能让机器自动学习客观对象的多层抽象和表示,从而理解各类复杂对象的内在含义,在计算机视觉等领域得到了广泛应用并取得了突出成效。随着ModelNet[4]、SHREC2015[5]等大型三维模型数据集的相继出现,在该领域也涌现出一系列深度学习的新算法[6-17]。然而,这些深度学习模型旨在完成元类型的识别,且假定测试样本和训练样本的类别相同;
当遇到特定需求,往往需要额外设计特定的模块来辅助网络进行特征提取。如,在细粒度分类[1]中需要设计局部特征提取模块以捕捉不同类型之间的局部差异,在零样本学习[3]中需要设计特定的关联模块以实现已知类到未知类的知识迁移。随着三维模型数量以及应用需求的不断增加,针对每种需求设计全新的网络无疑是耗时耗力,且十分困难的。
聚焦于以上问题,本文提出一种面向多样化分类任务的深度集成学习模型,在传统深度神经网络的基础上,加入集成模块,对网络初始决策进行再学习,根据任务需求的不同,使网络具有相应特征的提取能力;
并针对性地提出一种层次迭代式训练方法,通过初始网络-集成网络-整体网络的多层次训练策略,对网络进行迭代调优,协调网络中各个子模块的学习能力,使网络学习能力进一步提升,达到最优效果,从而自适应于不同需求的分类任务中。根据以上思想,设计一种通用三维模型分类网络,在确保分类性能的同时满足多样化分类需求。主要贡献体现在以下3个方面:
(1)面向多样化分类任务,设计了一种端到端的通用深度集成学习模型E2E-DEL(end-to-end deep ensemble learning),通过多个并行的初级学习器提取简单特征,形成初始决策,确保网络良好的泛化性能;
通过一个集成学习器完成特征融合,形成最终决策,有效适应多样化的分类需求。
(2)针对深度集成学习框架,提出一种层次迭代式训练方法,通过初级学习器和集成学习器的迭代调优策略,使网络训练更加充分,取得最优效果。
(3)基于以上框架,以三维模型的多视图为输入,构建了一种端到端的深度集成学习网络MV-DEL(multiview deep ensemble learning),应用于一般性、细粒度、零样本三种不同类型的三维模型分类任务中,性能优异。
面向三维模型的分类种类繁多,本文根据分类粒度的不同、测试集是否为训练中已见类别,选择了三种典型的、有区别性的需求组成多样化三维模型分类任务。如表1,包括:一般性三维模型分类、细粒度三维模型分类和零样本三维模型分类。考虑到现有工作均针对某一种分类需求设计特定算法,而基于深度学习的分类取得了当前最好的性能,本章将围绕深度学习分别介绍相关工作。
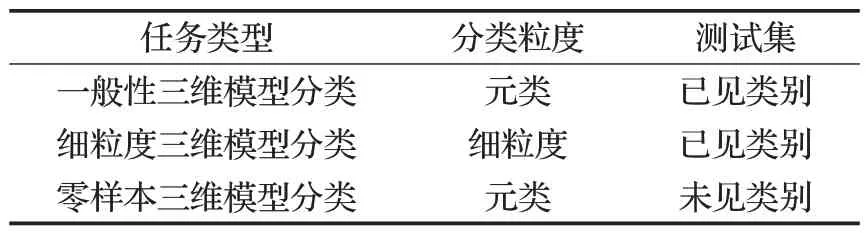
表1 三维模型多样化分类任务Table 1 Diversified 3D model classification tasks
1.1 一般性三维模型分类
如图1(a)所示,一般性三维模型分类中测试样本属于训练过程中已经见过的类别,聚焦于对元类,即粗粒度大类别的识别。考虑到深度学习网络对输入数据的结构化要求,早期的学者们将三维模型转化为特征向量的方式输入网络中,完成特征提取和分类[6]。由于在将三维模型转换为特征向量的过程中可能造成有益信息的丢失,后续学者开始考虑采用一些更为原始的结构化表征手段表征三维模型,满足深度学习网络输入要求的同时,尽可能地利用深度学习的特征自学习能力,包括基于体素的方法:3D ShapeNets[4]、VoxNet[7]等;
基于点云的方法:PointNet[8]、PointNet++[9]、PointCNN[10(]point convolutional neural network)、LightPointNet[11];
以及基于多视图的方法:MVCNN[12(]multi-view convolutional neural network)及 其 后 续 版 本[16]、DeepPano[13](deep panoramic representation)、GeometryImage[14(]geometry images)、CVS[15(]convolutional neural network and voting scheme)、SeqViews2SeqLabels[17](sequential views to sequential labels)、RotationNet[18]。整体来说,适应于不同三维模型表征形式的方法互有优劣:三维模型的体素表征可以直接编码三维模型的空间信息,但是对于硬件的要求较高;
点云是直接扫描三维物体获得,实时性较强,但伴随着稀疏、无序的特性,相关方法仍待完善;
多视图表征将三维模型表征成为多张二维图像,可以较好地利用二维图像领域成熟的图像处理技术,但如何有效地处理融合多个视图特征提高识别准确率仍然是该类方法的一个难点。

图1 三维模型多样化分类任务Fig.1 Diversified 3D model classification tasks
目前,在现有数据集下,基于深度学习的一般性三维模型分类任务已经取得了相当好的分类性能。然而,不可忽视的是,该任务中:(1)不同类目标对象在视觉上差异较大,因此其对应的深度学习网络只需要捕捉输入模型的整体特征即可;
(2)所有测试样本在训练过程中都已经见过,因此其对应的深度学习网络并不需要具备额外的迁移能力。因此,当分类的要求不断细化时,当测试时出现训练集中未曾出现的类时,这些网络的分类性能还需进一步评估。
1.2 细粒度三维模型分类
如图1(b)所示,细粒度三维模型分类中测试样本也属于训练过程中已经见过的类别,但是其聚焦于完成更细粒度类别的分类。由于待识别对象为来自一个元类的子类别,其整体视觉相似度极高。因此,针对细粒度分类的网络不仅需要提取三维模型的全局形状特征,还需要进一步捕捉差异性的局部细节区域,这给三维模型的细粒度分类带来了极大的挑战。
当前,面向三维模型的细粒度分类工作极少,已发表工作只有清华大学Liu等[19]所提出FG3D-Net(finegrained 3D shape classification network)。他们开创性地构建了一个面向细粒度三维模型分类的基准数据集FG3D,并专门性地设计了一种基于层次局部视图注意力机制的分类网络,取得了比较理想的效果。
相应地,在二维图像领域面向细粒度分类的研究较多。其中一类方法将分类任务分为两个阶段,首先通过特定的网络完成局部区域的定位,然后再通过特征提取网络提取鉴别性特征完成细粒度分类。典型工作有Ge等[20]提出的互补组件模型、Wang等[21]提出的判别性过滤学习网络DFL-CNN(discriminative filter learning-CNN)。另一类方法采用端到端的学习机制直接学习具有鉴别性的细粒度特征完成分类。其中最具代表性的方法是双线性网络Bilinear CNN[22],通过特征间相乘捕获高阶统计信息学习鉴别性局部特征,取得了当时最好的分类性能。此后,针对其特征相乘计算量和存储代价大的问题,出现了一系列改进工作,如基于低维度的双线性池化CBP[23(]compact bilinear pooling)、基于点乘的层次双 线 性池 化HBP[24(]hierarchical bilinear pooling)等。整体来说,在细粒度三维模型分类任务中,均需要相关的显著区域感知模块,网络规模与内存消耗较大;
在去掉此模块后,整体性能随之下降。
1.3 零样本三维模型分类
如图1(c)所示,零样本三维模型分类中测试样本属于训练过程中未曾见过的类别,即该任务具有训练类与测试类互斥的特点[25-26]。这种互斥性导致模型在训练阶段学习的知识无法直接应用于测试阶段,这就要求深度学习模型不仅仅具备特征学习能力,还需具有知识迁移能力,设计难度较大。
目前,在图像领域出现了一些零样本深度学习模型。其中一类工作通过将语义特征和视觉特征嵌入到一个公共空间的方式建立未知类和已知类间的关联,实现对未知类的有效识别,典型工作有Frome等[27]提出的DeViSE(deep visual-semantic embedding model)、Kodirov等[28]提出的SAE(semantic autoencoder)模型。另有一类工作通过生成网络为未知类生成图像特征完成分类,典型工作有Xian等[29]提出的f-CLSWGAN(feature classification Wasserstein generative adversarial network)以 及Sariyildiz等[30]提 出 的GMN(gradient matching networks)模型。
相比于二维图像,零样本学习在三维模型上的研究较少,仅有Cheraghian等研究小组先后发表了ZSLPC[31](zero-shot learning of 3D point cloud)、MHPC[32(]mitigating hubness problem of 3D point cloud)、TZLPC[33](transductive zero-shot learning for 3D point cloud)三篇工作。这些方法均以三维点云模型为输入,以点云特征提取网络为基础,加入特定的词向量嵌入网络,建立未知类和已知类之间的关联,完成零样本分类。整体来说,在零样本三维模型分类任务中,均需要设计额外的语义关联模块将已知类中的语义属性关联到未知类中去,网络结构复杂,分类性能不稳定。
综合来看,细粒度分类和零样本分类存在其特殊性,极具挑战性,面向三维的工作极少,而图像领域的研究全部都是针对该任务设计专门的网络,不存在一种通用的分类模型。研究一种适合于一般性、细粒度和零样本三维模型分类任务的通用深度学习模型极具挑战性。
通过分析可知,针对一般性、细粒度、零样本分类任务组成的多样化分类需求,拟设计的深度学习模型必须具备:(1)泛化性,即网络能够根据不同的任务需求学习形成不同的最终模型;
(2)自适应性,即可以提取多样化特征,并根据不同的任务需求自适应地选择最终特征完成分类;
(3)自学习性,即建立一种端到端的学习机制,自动根据任务完成学习。为此,本文将以以上三条为基本原则,设计一种通用的深度集成学习模型(见2.1节),提出深度集成损失函数(见2.2节),建立其层次式迭代训练机制(见2.3节),支持多样化分类。
2.1 深度集成学习模型E2E-DEL
在机器学习中,集成学习是一种构建并结合多个个体学习器来完成学习任务的学习机制。其中的个体学习器称作“初级学习器”,负责最终融合决策的学习器称作“集成学习器”。通过结合多个个体学习器,集成学习通常都会获得比单一学习器显著优越的泛化性能。
以此为启发,为满足多样化分类需求,本文构建了如图2所示的深度集成学习模型E2E-DEL:输入三维模型,通过随机采样等方式构建其所对应的多个结构化输入;
通过若干个相互独立的、并行的初级学习器提取每个随机采样输入的初始特征;
再通过最终的集成学习器融合多个初始特征形成最终特征;
据此完成相应的分类任务。下面将分别介绍该模型的各个部分。

图2 深度集成学习模型E2E-DELFig.2 End-to-end deep ensemble learning
2.1.1 结构化输入
针对深度集成学习模型中的若干个初级学习器,首先应对三维模型进行数据预处理,将三维模型表征为其可接受的数据输入形式。具体地,针对不同的三维模型表征,可设计以下几种不同的结构化输入:
(1)针对体素表征,可通过将三维模型旋转至不同角度再体素化构建多体素表征,也可通过不同分辨率的体素化构建多体素表征。
(2)针对点云表征,可构建不同分辨率的多点云表征,可通过多次随机撒点构建多点云表征。
(3)针对多视图表征,可利用虚拟相机在以三维模型重心为中心的球面上均匀放置摄像头采样获得多张二维视图,也可以采用MVCNN[12]中多视图构建方式在斜向上30°对应的圆上均匀放置摄像头采样获得多张二维视图。
此外,还可以考虑混合不同的三维模型表征获得多样化的输入。以上三种方式均为常用的三维模型表征形式,在工程应用中可根据实际任务中三维模型的表征形式以及相关硬件环境选择。
为方便统一表征,假定模型中的初级学习器个数为N,给定一个三维模型Mk,通过数据预处理后获得其结构化表示Mk={mik,1≤i≤N},其中1≤k≤K,K表示三维模型总数,mik为三维模型Mk的第i个输入,可以为以上表征中的任何一种形式。
2.1.2 初级学习器的构造
根据三维模型结构化输入Mk的不同可选用不同类型的深度学习网络组成初级学习器。若Mk中所包含的各个结构化输入mik形式相同,则可以考虑构造同质初级学习器,即多个初级学习器结构相同;
否则,可考虑构造异质初级学习器,即多个初级学习器结构不同。初级学习器的选择可采用适应于结构化输入的深度神经网络,如基于体素表征的VoxNet、基于点云表征的PointNet、基于二维图像的ResNet等。
针对每个初级学习器,为形成其初始决策,在特征提取层的最后加入一个初始决策层,由全连接FC和一个Softmax构成。假设待识别模型所属类别总数为C,则FC实现从输出特征向C维向量的映射,Softmax则将这C维向量转换为概率值,数值大小反应了输入模式属于某个类的概率。具体地,针对某个三维模型的结构化表征Mk={mik,1≤i≤N},对应的初级决策可表示为,其中Skij为根据第i个初级学习器判断三维模型Mk属于第j类的概率。
2.1.3 集成学习器的构造
根据初级学习器获得N个初始决策后,可进一步构造集成学习器完成综合决策。集成学习器的构造需要考虑初级决策的可信度,根据初级决策的准确性决定使用投票法或者学习法。具体如下:
(1)投票法
投票法分为绝对多数投票法、相对多数投票法和加权投票法三种。
绝对多数投票法的公式如下所示:
其中,Dk为第k个三维模型的最终分类结果。由公式可见,绝对投票法提供了拒绝预测的选项,当且仅当某个类在各个初级学习器上的概率总和超过整体概率值的50%,判定三维模型属于该类。这对准确性要求较高的学习任务是一个很好的机制,但有可能得不到预测结果。
相对多数投票法的公式如下所示:
式中,只需要某个类上在初级学习器上的概率总和最大,则判定三维模型属于该类;
若出现两个或者多个类概率和相同时,随机选择一个即可。
加权投票法的计算公式和公式(2)类似,不同的是考虑了各个初级学习器对最终投票结果的贡献,计算公式如下:
其中,wi表示初级学习器i的权重,可根据需求灵活设置不同初级学习器的权重,当w1=w2=…=wN=1/N时,加权投票法退化为相对多数投票法。该方法更加适应于类别相似度高,无法直接通过其他投票法获得最终决策的情况。
(2)学习法
投票法中的集成学习器是对初级决策进行投票选择的过程,难以根据具体学习任务建立自适应决策,更适应于单一任务。因此,为满足多样化分类需求,本小节将进一步设计具有自学习能力的集成学习器,可以对初级决策进行再学习使模型适应于不同的任务需求。将N个初级学习器的分类结果作为输入,可构造如图3所示的两种不同集成学习器,下面将分别介绍。

图3 不同集成方式Fig.3 Different ensemble ways
图3(a)给出了两种基于池化的集成学习器,分别由公式(4)和公式(5)表征如下:
其中,Dkm和Dka分别表示基于最大池化和平均池化得到的分类决策,f(∙)表示全连接和softmax操作。
图3(b)给出了基于拼接的集成学习器,由公式(6)表征如下:
其中,1≤i≤N,1≤j≤C,Dkc表示基于拼接得到的分类决策,f(∙)表示全连接和softmax操作。相比基于池化的集成学习器,拼接无信息丢失,能够更加完整地保留初级决策。
2.2 深度集成损失函数
进一步地,为训练图2所示的深度集成学习模型,本文提出了深度集成损失函数,由初级学习器和集成学习器两部分损失构成:
其中,Lt表示整个深度集成学习模型的损失,Lb和Le分别表示初级学习器和集成学习器的损失,α和β为对应的权重。集成学习器的损失可根据具体需求选择不同的函数,初级学习器的损失Li可通过下式计算:
其中,Li表示第i个初级学习器的损失,旨在衡量初级学习器i的预测标签和真实标签之间的差异,可根据具体需求选择相应函数;
αi表示第i个初级学习器损失函数的权重,可根据其采用同质、异质学习器的具体情况作出相应设置。
2.3 层次迭代式训练
整体上,初级学习器的损失同集成学习器的损失是正相关的;
然而,这两个损失函数的增长率并不完全一致,即,在训练过程中无法保证它们同时达到极值点。为此,针对深度集成学习模型的整体架构,本文设计了一种层次迭代式训练方法,包括以下4步。
步骤1初级学习器预训:可根据输入数据类型的不同选用预训练好的网络作为初级学习器,以保证初级学习器具有较好的初始参数,从而加快网络的收敛速度,获得更好的网络泛化性能。
步骤2整体网络初训:根据不同网络,设置训练步数,利用梯度下降和反向传播算法,当网络基本稳定,即总损失值达到稳定值后转入步骤3。
步骤3集成学习器调优:在整体网络达到平稳后,固定初级学习器内部参数,即每个初级学习器内部参数不参与反向传播,对集成学习器进行调优,只更新集成学习器内部的梯度。
步骤4初级学习器调优:当集成学习器调优结束后,固定集成学习器内部参数,即集成学习器内部参数不参与反向传播,对初级学习器进行调优,只更新初级学习器内部的梯度。
步骤5迭代或结束:当步骤3和步骤4中均无明显改善,总损失值达到稳定,不再继续减小时,训练结束;
否则,转入步骤2,再次进行调优。
本章将以深度集成学习模型E2E-DEL为原型,选择多视图的三维模型结构化表征形式,选择卷积神经网络组成初级学习器,使用全连接层构造集成学习器,最终构造多视图深度集成学习网络MV-DEL(multi-view deep ensemble learning),并将其应用于多样化分类任务中。
3.1 多视图深度集成学习网络MV-DEL
3.1.1 网络的构造
数据输入:采用Su-MVCNN[12]的多视图方法来表征三维模型,作为初级学习器的原始输入。具体地,给定一个三维模型,在单位球斜上方30°圆周上水平、均匀放置12个虚拟相机获得其多视图表征为Mk={vki,1≤i≤N},N=12。
初级学习器的选择:由于输入数据为12张视图,其数据属性类似,因此采用同质初级学习器的构造方式形成对每一张视图的初始决策。这里,可使用任何面向图像的深度卷积神经网络,如早期提出的AlexNet[34]、基于残差连接的ResNet[35],或者是轻量化的MobileNet[36]。本文中,不失一般性,采用ResNet50作为同质初级学习器,并通过参数共享的方式确保视图间特征提取的一致性。
集成学习器的构造:选用E2E-DEL中所设计的学习法完成集成学习器的构造,包括基于最大池化的集成学习器,基于平均池化的集成学习器和基于拼接的集成学习器。
3.1.2 损失函数的建立
针对每个初级学习器,选择交叉熵Cross Entropy Loss作为损失函数,有:
其中,K为样本数目,C为类别数目;
当第k个样本的预测标签lk与真实标签lk′相同时p{lk=lk′}取值为1,否则取值为0;
Skj表示第k个样本在第j维上的初级预测值。
进一步地,考虑到视图间的同质性,设各个初级学习器的权重相同,即α1=α2=…=αN=1N,则整个初级学习器的损失函数可表示为:
针对集成学习器,选用铰链损失衡量预测标签和真实标签之间的差异性,有:
其中,K为样本数目,C为分类数目;
δ{lk=lk′}为指示函数,当第k个样本的预测标签lk与真实标签lk′相同时,取值为1,否则取值为−1;
wjk表示第k个样本在第j维上的集成决策值。
整体损失按照公式(7)计算,根据实验,设置a=0.3,β=1.0。
3.1.3 网络的训练
步骤1初级学习器的预训:采用Pytorch官方提供的在Imagenet上预训好的ResNet50网络作为初级学习器。
步骤2整体网络初训:利用随机梯度下降SGD+牛顿动量法对网络进行整体训练,以确保网络收敛速度的同时,增强网络学习的稳定性。该阶段,学习率设为1×10−4,动量所占比重设为0.9;
当训练迭代5×102步此后,网络基本稳定,停止训练。
步骤3集成学习器调优:为确保网络的稳定性,更新学习率为初始学习率的1/100,并设置最大迭代次数为2×102步。若调优中,Loss趋于稳定或逐渐增大,可提前终止,转入下一步。
步骤4初级学习器调优:此时,学习率在步骤3的基础上再次降低10倍,并设置最大迭代次数为2×102。若调优中,Loss趋于稳定或逐渐增大,可提前终止,转入步骤5。
步骤5迭代或结束:当步骤3和步骤4中均无明显改善时,训练结束;
否则,固定学习率,转步骤2,再次进行调优。
训练中,为了增强网络的泛化能力,在生成训练集时随机打乱训练数据的排列顺序,以防止训练时单个批次中总是出现相同的训练样本。
3.2 多样化三维模型分类任务的构造
如表2所示,针对一般性三维模型分类任务,本文选用PrincetonModelNet[4]作为数据基准。沿用其他分类方法系统的设置:在ModelNet10中选取3 991个模型作为训练集,908个模型作为测试集;
在ModelNet40中选取9 843个模型作为训练集,2 468个模型作为测试集。

表2 面向一般性三维模型分类的数据集Table 2 Datasets for general 3D model classification
如表3所示,针对细粒度三维模型分类任务,本文选用Liu等[19]提出的FG3D数据集作为基准。该数据集包括三个类别的子数据集,其中Airplane数据集包含13个子类4 174个模型,Car数据集包含20个子类7 010个模型,Chair数据集包含33个子类11 124个模型。针对以上数据集,实验中沿用Liu等给出的训练集测试集划分方式,详情见表3。
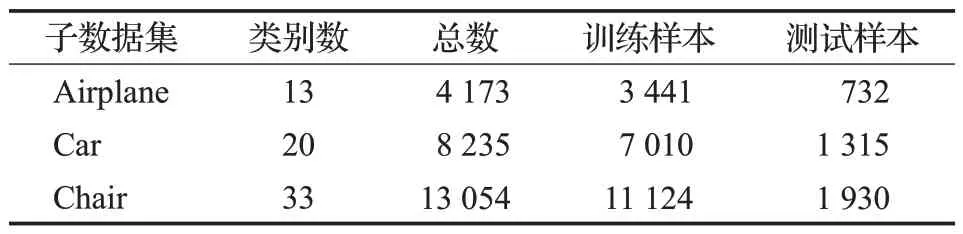
表3 面向细粒度三维模型分类的数据集Table 3 Datasets for fine-rigid 3D model classification
零样本分类任务与其他分类不同,需要划分已知类和未知类。如表4所示,本文选用Cheraghian等人所提出的数据集划分方式[31],将ModelNet40数据集中的30个类别作为已知类用作训练集,另外选择其他3个数据集ModelNet10、McGill和SHREC2015中与之互斥的10个、14个和30个类作为未知类用作测试。

表4 面向零样本三维模型分类的数据集Table 4 Datasets for zero-shot 3D model classification
实验的硬件环境为Intel Core i7 2600k+Tesla V100 32 GB+16 GB RAM,软件环境为Windows 10 x64+CUDA 10.0+CuDNN 7.1+Pytorch 1.1.0+Python3.6.5+Matlab。
4.1 消融实验
表5对比了不同初级学习器数目、是否采用集成学习器、不同集成学习器构造方法对网络性能的影响。实验中,选用传统三维模型分类数据集ModelNet10,利用MVCNN中所给出的视图获取方法[12]在圆周上均匀摆放4,8,12,…,80个虚拟摄像机,获得三维模型不同视图数目的多视图表征,构建包含对应数目初级学习器的多视图深度集成学习网络MV-DEL进行对比。表中MV-DEL1,2,3分别表示在集成网络中采用了最大池化、平均池化、拼接集成学习器。

表5 初级学习器数目&集成方式对分类精度的影响Table 5 Effects of number of base learners and ensemble learners on classification performance
表5展示了在ModelNet10数据集中不同初级学习器数目&不同集成方式对分类精度的影响,其中SD表示标准差。如表5所示,不同初级学习器数目下网络性能不同:当初级学习器数目从4、8逐渐增加到80,其分类性能的标准差分别为0.54、0.63、0.60、0.81,这说明不同初级学习器数目下网络性能稳定;
考虑到初级学习器数目为12时,分类性能相对优秀,计算开销较小,因此,后文实验中统一设置初级学习器数目为12。
纵向对比未使用集成学习器的算法MVCNN和使用了不同集成学习器的算法MV-DEL1,2,3可以发现:加入了集成学习器后,网络分类性能均得到了提升,由此表明加入集成学习器可以提升网络的分类性能。
此外,对比不同集成学习器对网络性能的影响可以发现:在视图数目较多的情况下,MV-DEL3方法的分类准确率高于MV-DEL1和MV-DEL2,这是因为相对于池化操作而言,基于拼接的集成学习方法可以更加完整地保留初始决策信息。对比两种基于池化的方法,可以发现在7种不同初级学习器数目下,MV-DEL1胜出4次,MV-DEL2胜出两次,且数值相差较小,即基于最大池化和平均池化的集成学习算法准确率相当。
表6对比了细粒度任务中不同集成方式对分类精度的影响,与表5中的结果类似:加入集成学习器的算法MV-DEL1,2,3分类准确率均高于未使用集成学习器的算法MVCNN;
在使用了集成学习器的算法中,基于拼接的集成学习算法MV-DEL3效果最优,基于最大池化MV-DEL1和平均池化MV-DEL2的集成学习算法效果相当。
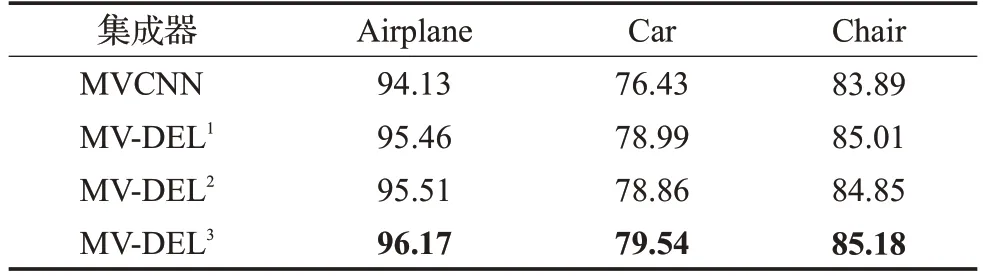
表6 不同集成方式对细粒度分类精度的影响Table 6 Effects of ensemble learners on fine-grained classification performance 单位:%
类似地,表7对比了零样本任务中不同集成方式对分类精度的影响,与之前实验得到了相同的结果:使用了集成学习器的算法效果均得到了提升,基于拼接的集成学习算法MV-DEL3取得了最优的分类准确率。
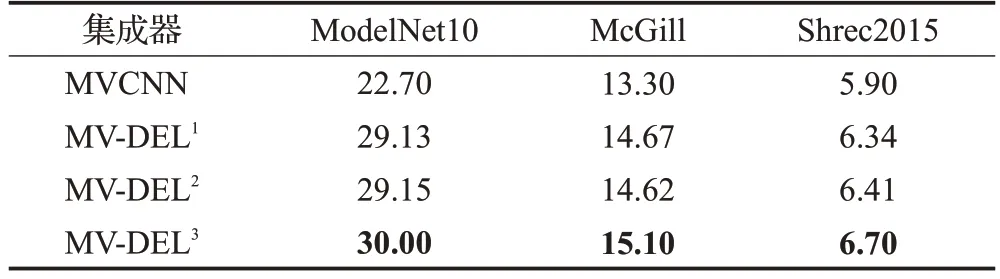
表7 不同集成方式对零样本分类精度的影响Table 7 Effects of different ensemble learners on zero-shot classification performance 单位:%
4.2 三维模型多样化分类实验对比
为充分测试本文方法在多样化三维模型分类任务中的分类性能与效率,本实验选取了基于多视图的经典三维模型分类方法MVCNN(VGG19)[12]、MVCNN(ResNet50)[12]、SeqView2SeqLabels(VAlexNet)[17]、Rotation-Net[18]、面向点云的经典三维模型分类方法PointNet[8]、专门为细粒度三维模型分类设计的方法FG3D-Net[19]、专门为零样本三维模型分类设计的方法ZSLPC[31]和MHPC[32]作为对比方法,进行综合对比。如表8所示,性能最优或者次优的方法分别在表中用加粗和下划线进行标识,所有对比方法的实验结果均来自已公开发表的论文,部分缺失数据表示为—。通过对比数据可知:

表8 三维模型多样化分类任务的分类准确率Table 8 Classification accuracy rates of diversified 3D model classification tasks
(1)在单分类需求下效果最佳的工作在面对不同需求的分类任务时表现欠佳,泛化性不足。例如在传统三维模型分类任务中表现最为优异的网络RotationNet在细粒度分类任务中性能并不理想,在Airplane、Car、Chair三个数据集上较最优方法分别相差大约3.41、3.95和3.11个百分点;
专门面向细粒度分类任务的FG3DNet和面向零样本分类的ZSLPC和MHPC因无公开代码,数据不足,无法直接评价。
(2)本文所提出的MV-DEL3在传统三维模型数据集ModelNet10、ModelNet40上分别取得了96.23%、94.15%的分类准确率,相比于同样是12视图以ResNet50为基网的MVCNN(ResNet50)在ModelNet40数据集上提升了4.05个百分点,相比于同样是12视图表征三维模型的SeqView2SeqLabels在ModelNet10和ModelNet40数据集上分别提升了1.41个百分点和0.75个百分点,仅次于当前最优的工作RotationNet;
在细粒度三维模型数据集Airplane、Chair和Car上分别取得了96.17%、79.54%、85.18%的分类精度,取得了目前最好的效果;
在零样本三维模型数据集ModelNet10取得了30.0%的分类精度,效果次优,在McGill和Shrec2015上分别取得了15.1%和6.7%的分类精度,效果最优。
(3)整体上看,由于点云具有稀疏性,点云类方法(PointNet、ZSLPC、MHPC)在参数量和推理时间两个效率评估指标中均优于多视图类方法(MVCNN-VGG19、
MVCNN-ResNet50、RotationNet、FG3D-Net、MV-DEL3)。在多视图类方法中,本文方法MV-DEL3的参数量仅次于MVCNN-VGG19,推理时间与MVCNN-ResNet50相当,表明了本文通过引入深度集成学习的思想,设计的多视图深度集成学习网络MV-DEL在满足了多样化分类需求的同时,几乎没有计算上额外的开销,整体规模较小,运算时间较短,是一种高效的方法。
综上,本文方法MV-DEL3在3类任务8个数据集上取得了5个最优分类准确率,3个次优分类准确率。这充分证明了在面对三维模型多样化分类任务时MV-DEL3具有良好的泛化性与普适性;
即使是面对非常困难的细粒度与零样本分类任务,仍然表现优异。
本文针对三维模型多样化分类问题,提出了一种端到端的深度集成学习模型E2E-DEL,通过多个并行的初级学习器形成初始决策保证确保网络良好的泛化性能,通过集成学习器形成自适应综合决策确保网络对多样化分类任务的适应能力;
基于此,本文选择了三维模型多视图的表征形式,设计了一种面向多视图的深度集成学习网络MV-DEL,应用于一般性、细粒度、零样本三种不同类型的三维模型分类任务中。实验结果表明:深度集成学习网络能够自适应于不同任务的特殊需求,学习到对应任务所需的深度模型,在面对三维模型多样化分类任务时,具有良好的泛化性与普适性。
目前,本文提出的深度集成学习网络还是基于同质初级学习器,即初级学习器都采用相同的网络结构。是否可以使用不同的网络结构组成功能各不相同的初级学习器,比如分别提取目标对象的轮廓与纹理等;
甚至使用面向不同类型输入数据的初级学习器,比如点云与多视图的混合输入,从而获得更佳性能将是进一步的研究方向。



